Coolpuppy python API walkthrough notebook¶
Please see https://github.com/open2c/open2c_examples for detailed explanation of how snipping and pileups work, and explanation of some terminology
# If you are a developer, you may want to reload the packages on a fly.
# Jupyter has a magic for this particular purpose:
%load_ext autoreload
%autoreload 2
# import standard python libraries
import matplotlib as mpl
%matplotlib inline
mpl.rcParams['figure.dpi'] = 96
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os, subprocess
# import libraries for biological data analysis
from coolpuppy import coolpup
from coolpuppy.lib import numutils
from coolpuppy.lib.puputils import divide_pups
from coolpuppy import plotpup
import cooler
import bioframe
import cooltools
from cooltools import expected_cis, expected_trans
from cooltools.lib import plotting
Download data¶
For the test, we collected the data from immortalized human foreskin fibroblast cell line HFFc6:
Micro-C data from Krietenstein et al. 2020
ChIP-Seq for CTCF from ENCODE ENCSR000DWQ
You can automatically download test datasets with cooltools. More information on the files and how they were obtained is available from the datasets description.
# Print available datasets for download
cooltools.print_available_datasets()
1) HFF_MicroC : Micro-C data from HFF human cells for two chromosomes (hg38) in a multi-resolution mcool format. Krietenstein et al. 2021 data.
Downloaded from https://osf.io/3h9js/download
Stored as test.mcool
Original md5sum: e4a0fc25c8dc3d38e9065fd74c565dd1
2) hESC_MicroC : Micro-C data from human ES cells for two chromosomes (hg38) in a multi-resolution mcool format. Krietenstein et al. 2021 data.
Downloaded from https://osf.io/3kdyj/download
Stored as test_hESC.mcool
Original md5sum: ac0e636605505fb76fac25fa08784d5b
3) HFF_CTCF_fc : ChIP-Seq fold change over input with CTCF antibodies in HFF cells (hg38). Downloaded from ENCODE ENCSR000DWQ, ENCFF761RHS.bigWig file
Downloaded from https://osf.io/w92u3/download
Stored as test_CTCF.bigWig
Original md5sum: 62429de974b5b4a379578cc85adc65a3
4) HFF_CTCF_binding : Binding sites called from CTCF ChIP-Seq peaks for HFF cells (hg38). Peaks are from ENCODE ENCSR000DWQ, ENCFF498QCT.bed file. The motifs are called with gimmemotifs (options --nreport 1 --cutoff 0), with JASPAR pwm MA0139.
Downloaded from https://osf.io/c9pwe/download
Stored as test_CTCF.bed.gz
Original md5sum: 61ecfdfa821571a8e0ea362e8fd48f63
5) mESC_dRad21_IAA : Micro-C data from mESC for three chromosomes (mm10) in a multi-resolution mcool format (Hsieh et al. 2022). dRad21 IAA treatment, degraded Rad21.
Downloaded from https://osf.io/wy2mh/download
Stored as dRAD21_IAA.mm10.mapq_30.mcool
Original md5sum: a68e4c57f15d2f0ba3b0bb9d7c4066a2
6) mESC_dRad21_UT : Micro-C data from mESC for three chromosomes (mm10) in a multi-resolution mcool format (Hsieh et al. 2022). dRad21 untreated (UT), control for Rad21 degradation.
Downloaded from https://osf.io/z83wv/download
Stored as dRAD21_UT.mm10.mapq_30.mcool
Original md5sum: 1028b3f9fce7d77c9dc73d5e6b77d078
7) mESC_dCTCF_IAA : Micro-C data from mESC for three chromosomes (mm10) in a multi-resolution mcool format (Hsieh et al. 2022). dCTCF IAA treatment, degraded CTCF.
Downloaded from https://osf.io/79qje/download
Stored as dCTCF_IAA.mm10.mapq_30.mcool
Original md5sum: 84fea965b341e0110df63bc06b7f1d77
8) mESC_dWapl_IAA : Micro-C data from mESC for three chromosomes (mm10) in a multi-resolution mcool format (Hsieh et al. 2022). dWapl IAA treatment, degraded Wapl.
Downloaded from https://osf.io/etdgf/download
Stored as dWAPL_IAA.mm10.mapq_30.mcool
Original md5sum: 1514422b821c0f96757e76e98a6507b5
# Downloading test data for pileups
# cache = True will download the data only if it was not previously downloaded
# data_dir="./" will force download to the current directory
cool_file = cooltools.download_data("HFF_MicroC", cache=True, data_dir='./')
ctcf_peaks_file = cooltools.download_data("HFF_CTCF_binding", cache=True, data_dir='./')
ctcf_fc_file = cooltools.download_data("HFF_CTCF_fc", cache=True, data_dir='./')
resolution = 10000
# Open cool file with Micro-C data:
clr = cooler.Cooler(f'{cool_file}::/resolutions/{resolution}')
# Use bioframe to fetch the genomic features from the UCSC.
hg38_chromsizes = bioframe.fetch_chromsizes('hg38')
hg38_cens = bioframe.fetch_centromeres('hg38')
hg38_arms = bioframe.make_chromarms(hg38_chromsizes, hg38_cens)
# Select only chromosomes that are present in the cooler.
# This step is typically not required! we call it only because the test data are reduced.
hg38_arms = hg38_arms.set_index("chrom").loc[clr.chromnames].reset_index()
# call this to automaticly assign names to chromosomal arms:
hg38_arms = bioframe.make_viewframe(hg38_arms)
hg38_arms
| chrom | start | end | name | |
|---|---|---|---|---|
| 0 | chr2 | 0 | 93139351 | chr2_p |
| 1 | chr2 | 93139351 | 242193529 | chr2_q |
| 2 | chr17 | 0 | 24714921 | chr17_p |
| 3 | chr17 | 24714921 | 83257441 | chr17_q |
hg38_arms.to_csv('hg38_arms.bed', sep='\t', header=False, index=False) # To use in CLI
# Read CTCF peaks data and select only chromosomes present in cooler:
ctcf = bioframe.read_table(ctcf_peaks_file, schema='bed').query(f'chrom in {clr.chromnames}')
ctcf['mid'] = (ctcf.end+ctcf.start)//2
ctcf.head()
| chrom | start | end | name | score | strand | mid | |
|---|---|---|---|---|---|---|---|
| 17271 | chr17 | 118485 | 118504 | MA0139.1_CTCF_human | 12.384042 | - | 118494 |
| 17272 | chr17 | 144002 | 144021 | MA0139.1_CTCF_human | 11.542617 | + | 144011 |
| 17273 | chr17 | 163676 | 163695 | MA0139.1_CTCF_human | 5.294219 | - | 163685 |
| 17274 | chr17 | 164711 | 164730 | MA0139.1_CTCF_human | 11.889376 | + | 164720 |
| 17275 | chr17 | 309416 | 309435 | MA0139.1_CTCF_human | 7.879575 | - | 309425 |
import bbi
# Get CTCF ChIP-Seq fold-change over input for genomic regions centered at the positions of the motifs
flank = 250 # Length of flank to one side from the boundary, in basepairs
ctcf_chip_signal = bbi.stackup(
ctcf_fc_file,
ctcf.chrom,
ctcf.mid-flank,
ctcf.mid+flank,
bins=1)
ctcf['FC_score'] = ctcf_chip_signal
ctcf['quartile_score'] = pd.qcut(ctcf['score'], 4, labels=False) + 1
ctcf['quartile_FC_score'] = pd.qcut(ctcf['FC_score'], 4, labels=False) + 1
ctcf['peaks_importance'] = ctcf.apply(
lambda x: 'Top by both scores' if x.quartile_score==4 and x.quartile_FC_score==4 else
'Top by Motif score' if x.quartile_score==4 else
'Top by FC score' if x.quartile_FC_score==4 else 'Ordinary peaks', axis=1
)
# Select the CTCF sites that are in top quartile by both the ChIP-Seq data and motif score
sites = ctcf[ctcf['peaks_importance']=='Top by both scores']\
.sort_values('FC_score', ascending=False)\
.reset_index(drop=True)
sites.tail()
| chrom | start | end | name | score | strand | mid | FC_score | quartile_score | quartile_FC_score | peaks_importance | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 659 | chr17 | 8158938 | 8158957 | MA0139.1_CTCF_human | 13.276979 | - | 8158947 | 25.056849 | 4 | 4 | Top by both scores |
| 660 | chr2 | 176127201 | 176127220 | MA0139.1_CTCF_human | 12.820343 | + | 176127210 | 25.027294 | 4 | 4 | Top by both scores |
| 661 | chr17 | 38322364 | 38322383 | MA0139.1_CTCF_human | 13.534864 | - | 38322373 | 25.010430 | 4 | 4 | Top by both scores |
| 662 | chr2 | 119265336 | 119265355 | MA0139.1_CTCF_human | 13.739862 | - | 119265345 | 24.980141 | 4 | 4 | Top by both scores |
| 663 | chr2 | 118003514 | 118003533 | MA0139.1_CTCF_human | 12.646685 | - | 118003523 | 24.957502 | 4 | 4 | Top by both scores |
sites.to_csv('annotated_ctcf_sites.tsv', sep='\t', index=False, header=False) # Let's save to use in CLI
On-diagonal pileup¶
On-diagonal pileup is the simplest, you need the positions of features (middlepoints of CTCF motifs) and the size of flanks aroung each motif. Coolpuppy will aggregate all snippets around each motif with the specified normalization.
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms, local=True,
flank=300_000, min_diag=0)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 144
INFO:coolpuppy:('chr2_q', 'chr2_q'): 202
INFO:coolpuppy:('chr17_p', 'chr17_p'): 78
INFO:coolpuppy:('chr17_q', 'chr17_q'): 239
INFO:coolpuppy:Total number of piled up windows: 663
This is the general format of output of coolpuppy pileup functions: a pandas dataframe with columns “data” and “n” - “data” contains pileups as numpy arrays, and “n” - number of snippets used to generate this pileup.
Different kinds of pileups calculated in one run are stored as rows, and their groups are annotated in the columns preceding “data”. Since here we didn’t split the data into any groups, there is only one pileup with group “all”
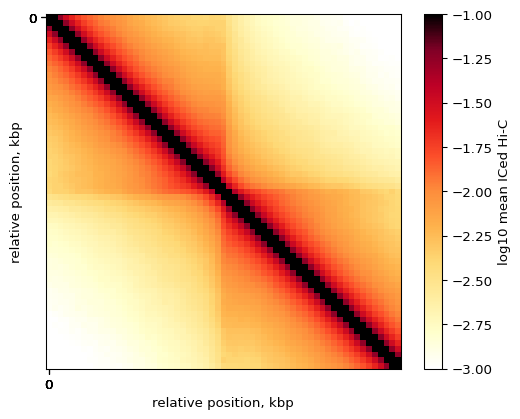
Let’s visualize the average Hi-C map at all strong CTCF sites:
plt.imshow(
np.log10(pup.loc[0, 'data']),
vmax = -1,
vmin = -3.0,
cmap='fall',
interpolation='none')
plt.colorbar(label = 'log10 mean ICed Hi-C')
ticks_pixels = np.linspace(0, flank*2//resolution,5)
ticks_kbp = ((ticks_pixels-ticks_pixels[-1]/2)*resolution//1000).astype(int)
plt.xticks(ticks_pixels, ticks_kbp)
plt.yticks(ticks_pixels, ticks_kbp)
plt.xlabel('relative position, kbp')
plt.ylabel('relative position, kbp')
plt.show()
By-strand pileups¶
Now, we know that orientation of the CTCF site is very important for the interactions it forms. Using coolpuppy, splitting regions by the strand is trivial, expecially using a convenience function:
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms, local=True,
by_strand=True,
flank=300_000, min_diag=0)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 144
INFO:coolpuppy:('chr2_q', 'chr2_q'): 202
INFO:coolpuppy:('chr17_p', 'chr17_p'): 78
INFO:coolpuppy:('chr17_q', 'chr17_q'): 239
INFO:coolpuppy:Total number of piled up windows: 663
pup
| orientation | strand2 | strand1 | group | data | n | num | clr | resolution | flank | ... | flip_negative_strand | ignore_diags | store_stripes | nproc | ignore_group_order | by_window | by_strand | by_distance | groupby | cooler | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -- | - | - | (-, -) | [[1.8388677780141118, 0.3035714543313729, 0.05... | 326 | [[307, 307, 307, 306, 306, 306, 306, 307, 307,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | ... | False | 0 | False | 1 | False | False | True | False | [] | test |
| 1 | ++ | + | + | (+, +) | [[1.8534148775587997, 0.2993882425820983, 0.05... | 337 | [[325, 324, 324, 322, 322, 320, 320, 321, 320,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | ... | False | 0 | False | 1 | False | False | True | False | [] | test |
| 2 | all | all | all | all | [[1.846348485849592, 0.30142349774378974, 0.05... | 663 | [[632.0, 631.0, 631.0, 628.0, 628.0, 626.0, 62... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | ... | False | 0 | False | 1 | False | False | True | False | [] | test |
3 rows × 40 columns
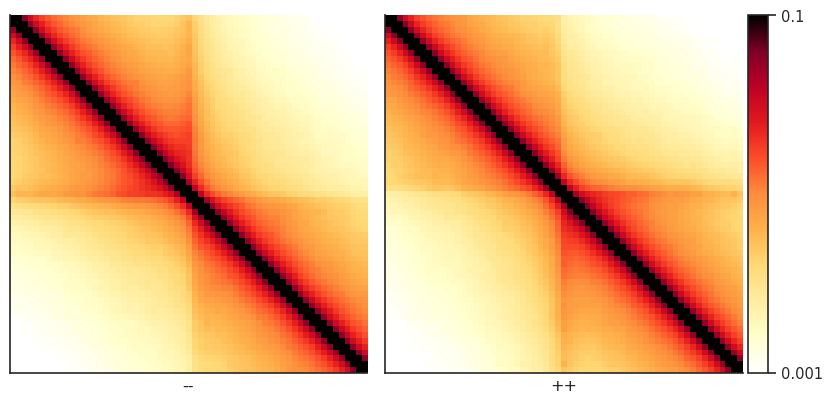
Now we can use a convenient seaborn-based function from the plotpup.py subpackage to create a grid of heatmaps based on by-row and/or by-column variable mapping. In this case, we just map two orientations of CTCF sites across columns.
sns.set_theme(font_scale=2, style="ticks")
plotpup.plot(pup,
cols='orientation', col_order=['--', '++'],
score=False, cmap='fall', scale='log', sym=False,
vmin=0.001, vmax=0.1,
height=5)
<seaborn.axisgrid.FacetGrid at 0x2aaafb6bb5b0>
Pileups of observed over expected interactions¶
Sometimes you don’t want to include the distance decay P(s) in your pileups. For example, when you make comparison of pileups between experiments and they have different P(s). Even if these differences are slight, they might affect the pileup of raw ICed Hi-C interactions. Moreover, without controlling for it the range of values in the pileup is not very easy to guess before plotting.
In this case, the observed over expected pileup is your choice. To normalize your pileup to the background level of interactions, you can either, prior to running the pileup function, calculate expected interactions for each chromosome arms, or you can generate randomly shifted control regions for each snippet, and divide the final pileup by that control pileup.
Let’s first try the latter. This analysis is particulalry useful for single-cell Hi-C where the data might be too sparse to generate robust per-diagonal expected values.
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms, local=True,
by_strand=True, nshifts=10,
flank=300_000, min_diag=0)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 144
INFO:coolpuppy:('chr2_q', 'chr2_q'): 202
INFO:coolpuppy:('chr17_p', 'chr17_p'): 78
INFO:coolpuppy:('chr17_q', 'chr17_q'): 239
INFO:coolpuppy:Total number of piled up windows: 663
plotpup.plot(pup,
cols='orientation', col_order=['--', '++'],
score=False, cmap='coolwarm', scale='log', sym=True,
vmax=2,
height=5)
<seaborn.axisgrid.FacetGrid at 0x2aaafbb845b0>
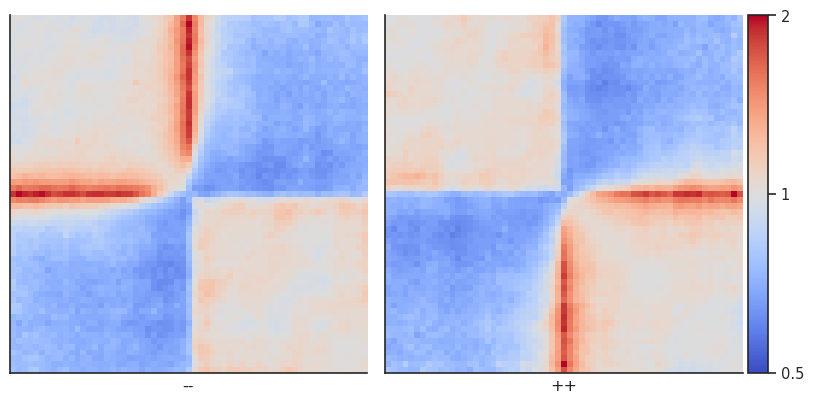
As you can see, this strongly highlights the depletion of interactions across the CTCF sites, and enrichment of interactions in a stripe starting from the site.
Now let’s calculate per-diagonal expected level of interactions to repeat the analysis using that.
# Calculate expected interactions for chromosome arms
expected = expected_cis(
clr,
ignore_diags=0,
view_df=hg38_arms,
chunksize=1000000)
expected.to_csv('test_expected_cis.tsv', sep='\t', index=False, header=True) # Let's save to use in CLI
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms, local=True,
expected_df=expected, by_strand=True,
flank=300_000, min_diag=0)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 144
INFO:coolpuppy:('chr2_q', 'chr2_q'): 202
INFO:coolpuppy:('chr17_p', 'chr17_p'): 78
INFO:coolpuppy:('chr17_q', 'chr17_q'): 239
INFO:coolpuppy:Total number of piled up windows: 663
plotpup.plot(pup,
cols='orientation', col_order=['--', '++'],
score=False, cmap='coolwarm', scale='log',
sym=True, vmax=2,
height=5)
<seaborn.axisgrid.FacetGrid at 0x2aaafbb2cee0>
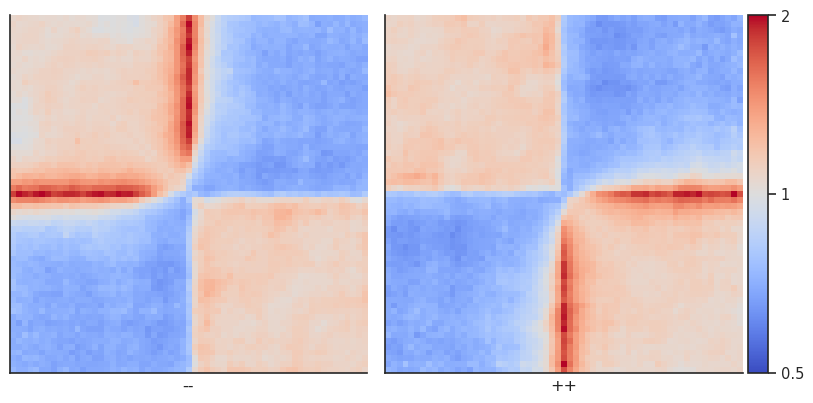
The result is almost identical!
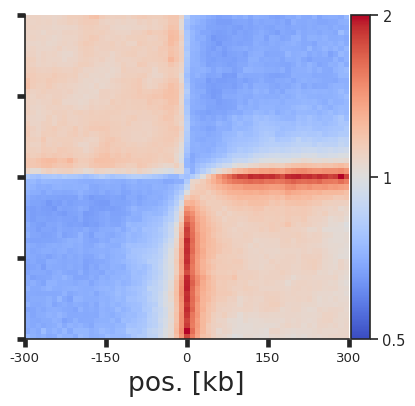
Instead of splitting two strands into two separate pileups, one can also flip the features on the negative strand using flip_negative_strand. This way a single pileup is created where all features face in the same direction (as if they were on the positive strand). We can also add plot_ticks=True to show the central and flanking coordinates on the bottom of the plot.
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms, local=True,
expected_df=expected, flip_negative_strand=True,
flank=300_000, min_diag=0)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 144
INFO:coolpuppy:('chr2_q', 'chr2_q'): 202
INFO:coolpuppy:('chr17_p', 'chr17_p'): 78
INFO:coolpuppy:('chr17_q', 'chr17_q'): 239
INFO:coolpuppy:Total number of piled up windows: 663
plotpup.plot(pup,
score=False, cmap='coolwarm', scale='log',
sym=True, vmax=2,
height=5, plot_ticks=True)
<seaborn.axisgrid.FacetGrid at 0x2aab1eb78340>
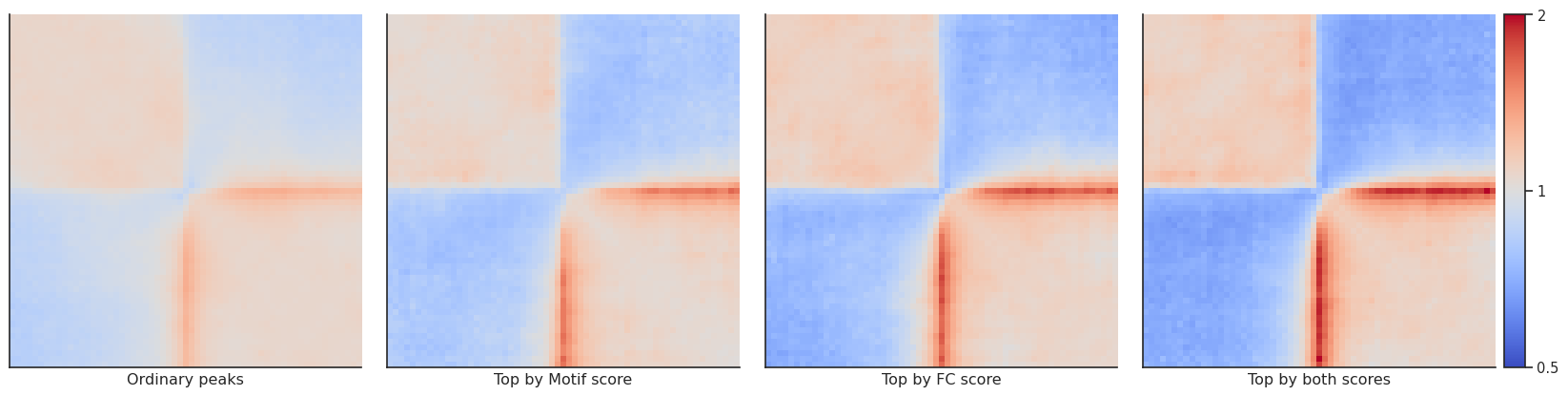
Arbitrary grouping of snippets for pileups¶
Now, let’s see how our selection of only top CTCF peaks affects the results. We could simply repeat the analysis with the rest of CTCF peaks, but to showcase the power of coolpuppy, we’ll demonstrate how it can be used to generate pileups split be arbitrary categories
pup = coolpup.pileup(clr, ctcf, features_format='bed', view_df=hg38_arms, local=True,
expected_df=expected, flip_negative_strand=True,
groupby=['peaks_importance1'],
flank=300_000, min_diag=0)
# Splitting all snippets into groups based on annotated previously importance of the peaks
# Also flipping negative stranded features as shown above.
INFO:coolpuppy:('chr2_p', 'chr2_p'): 1381
INFO:coolpuppy:('chr2_q', 'chr2_q'): 2221
INFO:coolpuppy:('chr17_p', 'chr17_p'): 548
INFO:coolpuppy:('chr17_q', 'chr17_q'): 1602
INFO:coolpuppy:Total number of piled up windows: 5752
pup
| peaks_importance1 | group | data | n | num | clr | resolution | flank | rescale_flank | chroms | ... | flip_negative_strand | ignore_diags | store_stripes | nproc | ignore_group_order | by_window | by_strand | by_distance | groupby | cooler | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Ordinary peaks | (Ordinary peaks,) | [[1.0699452226771298, 1.0642211188669746, 1.07... | 3536 | [[3432, 3421, 3412, 3413, 3403, 3404, 3402, 33... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | None | ['chr2', 'chr17'] | ... | True | 0 | False | 1 | False | False | False | False | [peaks_importance1] | test |
| 1 | Top by FC score | (Top by FC score,) | [[1.0829924317033595, 1.1009490059442415, 1.09... | 778 | [[745, 740, 741, 739, 739, 737, 739, 736, 734,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | None | ['chr2', 'chr17'] | ... | True | 0 | False | 1 | False | False | False | False | [peaks_importance1] | test |
| 2 | Top by Motif score | (Top by Motif score,) | [[1.0288083600349012, 1.0363397675639456, 1.03... | 775 | [[750, 749, 746, 744, 746, 741, 743, 743, 739,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | None | ['chr2', 'chr17'] | ... | True | 0 | False | 1 | False | False | False | False | [peaks_importance1] | test |
| 3 | Top by both scores | (Top by both scores,) | [[1.0773804769093807, 1.0932965447911036, 1.09... | 663 | [[640, 638, 638, 635, 634, 632, 631, 630, 629,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | None | ['chr2', 'chr17'] | ... | True | 0 | False | 1 | False | False | False | False | [peaks_importance1] | test |
| 4 | all | all | [[1.067003977204076, 1.0686994220484458, 1.072... | 5752 | [[5567.0, 5548.0, 5537.0, 5531.0, 5522.0, 5514... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | 10000 | 300000 | None | ['chr2', 'chr17'] | ... | True | 0 | False | 1 | False | False | False | False | [peaks_importance1] | test |
5 rows × 38 columns
fg = plotpup.plot(pup.reset_index(), # Simply resetting the index makes the output directly compatible with the plotting function -
# just need to remember there is also a group "all" which you might not want to show
cols='peaks_importance1',
col_order=['Ordinary peaks', 'Top by Motif score',
'Top by FC score', 'Top by both scores'],
score=False, cmap='coolwarm',
scale='log', sym=True, vmax=2,
height=5)
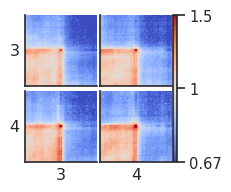
We can also compare interactions between regions (local=False) using the groupby function. However, we need to specify two groups, in this case “quartile_score1” and “quartile_score2”. To limit the number of regions, we use subset with a set seed for reproducibility
pup = coolpup.pileup(clr, ctcf.loc[ctcf["quartile_score"] > 2], features_format='bed', view_df=hg38_arms,
local=False, expected_df=expected,
groupby=['quartile_score1', 'quartile_score2'],
flank=300_000, mindist=300_000, maxdist=600_000,
subset=2000, seed=1, nproc=2)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 957
INFO:coolpuppy:('chr2_q', 'chr2_q'): 1383
INFO:coolpuppy:('chr17_p', 'chr17_p'): 506
INFO:coolpuppy:('chr17_q', 'chr17_q'): 1963
INFO:coolpuppy:Total number of piled up windows: 4809
fg = plotpup.plot(pup.loc[pup["quartile_score1"] != "all"].reset_index(),
cols='quartile_score1',
rows='quartile_score2',
score=False, cmap='coolwarm',
scale='log', sym=True, vmax=1.5,
height=1)
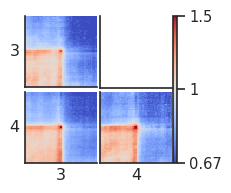
Here we can see all combinations of interactions between quartiles 3 and 4. However, in this case quartile 3-4 and 4-3 interactions are equivalent. To combine them into one (taking into account orientation), we can use the setting ignore_group_order
pup = coolpup.pileup(clr, ctcf.loc[ctcf["quartile_score"] > 2], features_format='bed', view_df=hg38_arms,
local=False, expected_df=expected,
groupby=['quartile_score1', 'quartile_score2'],
ignore_group_order="quartile_score",
flank=300_000, mindist=300_000, maxdist=600_000,
subset=2000, seed=1, nproc=2)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 957
INFO:coolpuppy:('chr2_q', 'chr2_q'): 1383
INFO:coolpuppy:('chr17_p', 'chr17_p'): 506
INFO:coolpuppy:('chr17_q', 'chr17_q'): 1963
INFO:coolpuppy:Total number of piled up windows: 4809
fg = plotpup.plot(pup.loc[pup["quartile_score1"] != "all"].reset_index(),
cols='quartile_score1',
rows='quartile_score2',
score=False, cmap='coolwarm',
scale='log', sym=True, vmax=1.5,
height=1)
By-distance pileups¶
As it is known, CTCF sites frequently have peaks of Hi-C interactions between them, that indicate chromatin loops. Let’s see at what distances they tend to occur, and let’s see what patterns these regions form at different distance separations and different motif orientations.
Since we generate many more snippets than for local (on-diagonal) pileups, it will take a little longer to run. We can use the nproc argument to use multiprocessing and run it in parallel to speed it up a bit. Note that parallelization requires more RAM, so use with caution.
# Using all strong sites here to make it faster
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms,
expected_df=expected, flip_negative_strand=True,
by_distance=True, by_strand=True, mindist=100_000,
flank=300_000, min_diag=0,
nproc=2
)
# Splitting all snippets into groups based on strand and separation between two sites
INFO:coolpuppy:('chr2_p', 'chr2_p'): 10250
INFO:coolpuppy:('chr17_p', 'chr17_p'): 2959
INFO:coolpuppy:('chr2_q', 'chr2_q'): 20215
INFO:coolpuppy:('chr17_q', 'chr17_q'): 28284
INFO:coolpuppy:Total number of piled up windows: 61708
pup.head()
| separation | orientation | distance_band | strand2 | strand1 | group | data | n | num | clr | ... | flip_negative_strand | ignore_diags | store_stripes | nproc | ignore_group_order | by_window | by_strand | by_distance | groupby | cooler | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.1Mb-\n0.2Mb | ++ | (100000, 200000) | + | + | (+, +, (100000, 200000)) | [[1.0169219164613472, 0.9600852237815437, 1.01... | 67 | [[64, 66, 66, 65, 66, 65, 63, 65, 65, 65, 65, ... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | ... | True | 0 | False | 2 | False | False | True | True | [] | test |
| 1 | 0.2Mb-\n0.4Mb | ++ | (200000, 400000) | + | + | (+, +, (200000, 400000)) | [[0.8621663934782983, 0.8441139544987121, 0.85... | 131 | [[125, 126, 126, 126, 126, 126, 125, 126, 126,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | ... | True | 0 | False | 2 | False | False | True | True | [] | test |
| 2 | 0.4Mb-\n0.8Mb | ++ | (400000, 800000) | + | + | (+, +, (400000, 800000)) | [[0.6943248290614478, 0.6951043361705603, 0.68... | 245 | [[236, 236, 236, 236, 236, 236, 236, 236, 236,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | ... | True | 0 | False | 2 | False | False | True | True | [] | test |
| 3 | 0.8Mb-\n1.6Mb | ++ | (800000, 1600000) | + | + | (+, +, (800000, 1600000)) | [[0.6474314279066417, 0.6349530137034375, 0.68... | 425 | [[390, 390, 390, 390, 394, 389, 389, 393, 393,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | ... | True | 0 | False | 2 | False | False | True | True | [] | test |
| 4 | 1.6Mb-\n3.2Mb | ++ | (1600000, 3200000) | + | + | (+, +, (1600000, 3200000)) | [[0.8110724673135341, 0.8450568161843092, 0.79... | 789 | [[727, 727, 727, 727, 732, 727, 718, 736, 734,... | /gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy... | ... | True | 0 | False | 2 | False | False | True | True | [] | test |
5 rows × 42 columns
fg = plotpup.plot(pup, rows='orientation', cols='separation',
row_order=['-+', '--', '++', '+-'],
score=False, cmap='coolwarm', scale='log', sym=True, vmax=3,
height=3)
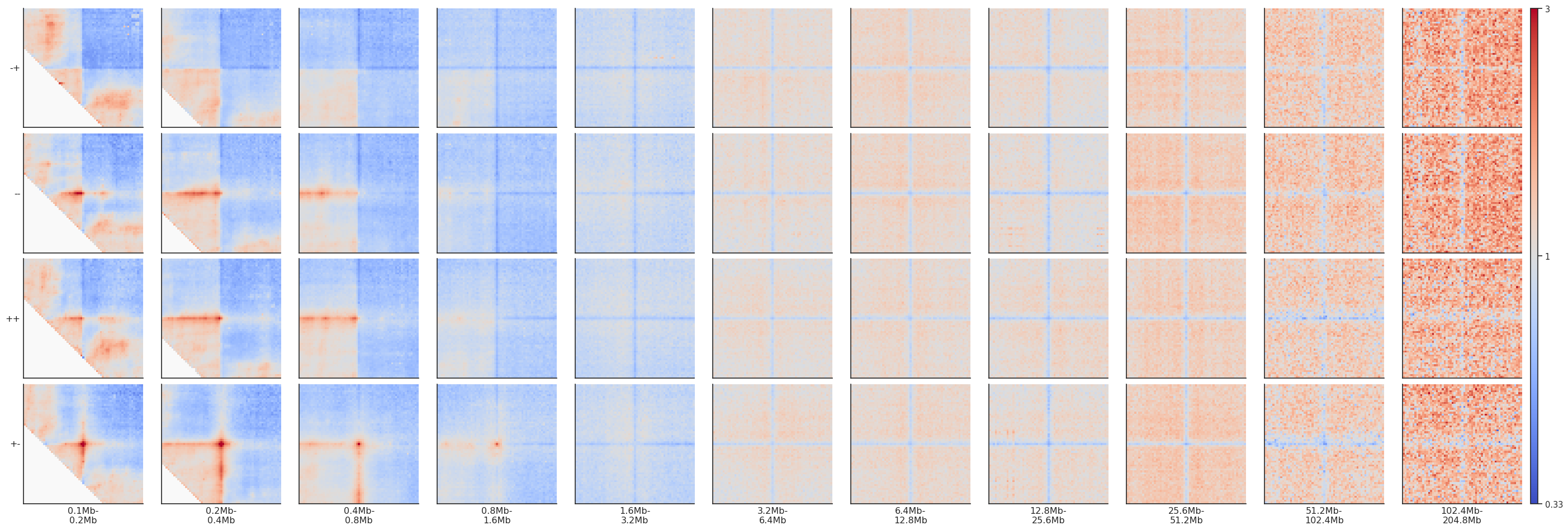
Note that since CTCF sites are preferentially found in the A compartment, the expected level of interactions at different distances varies, generating different background interaction levels. We can artificially fix that by normalizing each pileup by the average interactions in the top-left and bottom-right corners.
fg = plotpup.plot(pup, rows='orientation', cols='separation',
row_order=['-+', '--', '++', '+-'],
score=False, cmap='coolwarm', scale='log', sym=True, vmax=3,
norm_corners=10,
height=3)
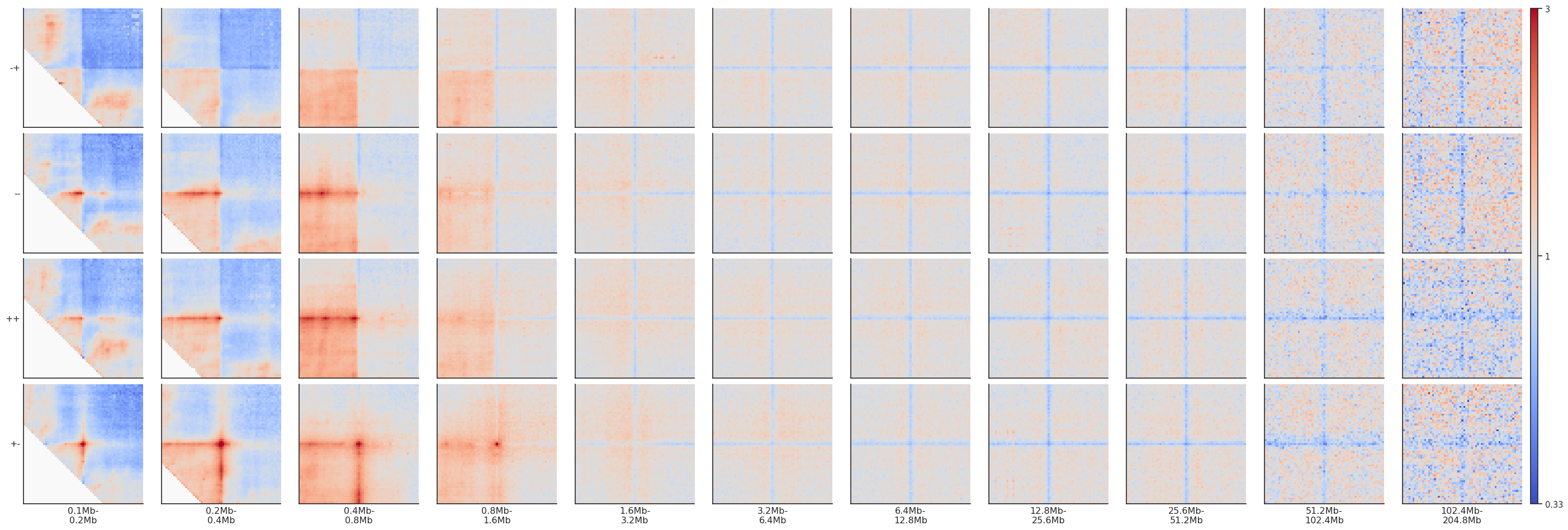
If you want to actually modify the data in your dataframe to normalize to the corners and not just apply it for vizualisation, you can do that explicitly:
pup['data'] = pup['data'].apply(numutils.norm_cis, i=10)
A good idea to give some more quantitative information about the level of enrichment of interactions in the center of the pileup is to just label the average value of the few central pixels of the heatmap. The simplest way is to use the argument score:
fg = plotpup.plot(pup, rows='orientation', cols='separation',
row_order=['-+', '--', '++', '+-'],
score=True,
cmap='coolwarm', scale='log', sym=True, vmax=3,
height=3)
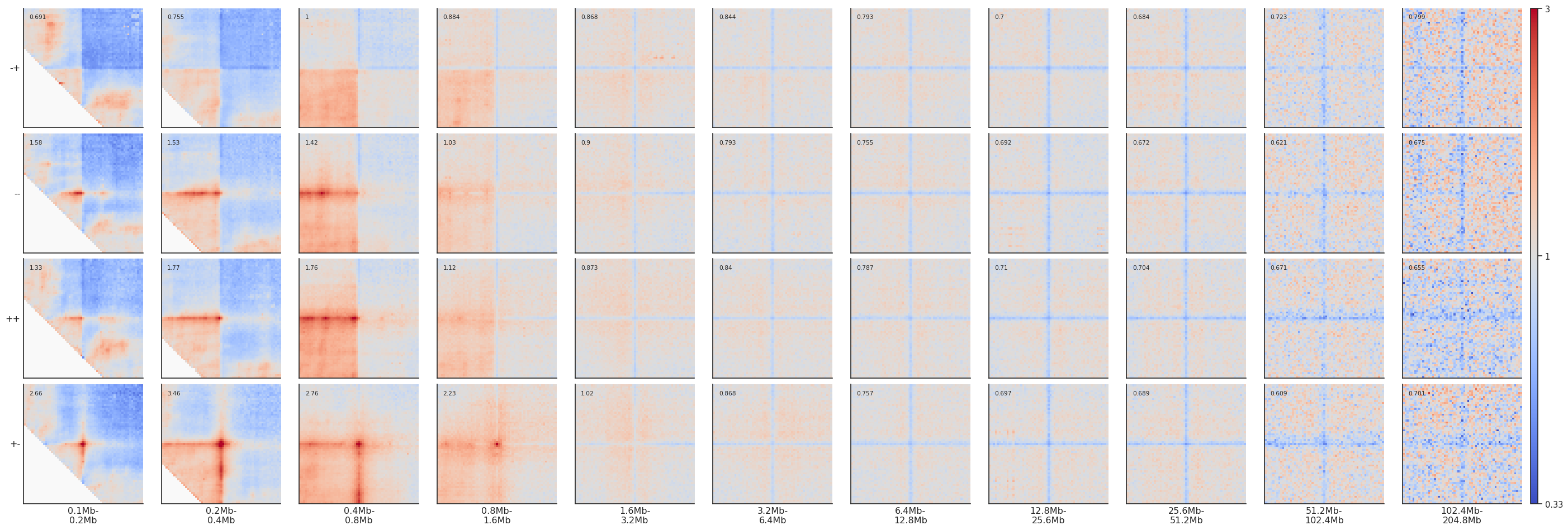
Dividing pileups¶
Sometimes you may want to compare two pileups directly and plot the result of the division between them. For this we can use the divide_pups function. Let’s look at all CTCF interactions between 100 kb and 1 Mb by motif orientation.
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms,
expected_df=expected,
by_strand=True, mindist=100_000, maxdist=1_000_000,
flank=300_000, nproc=2)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 287
INFO:coolpuppy:('chr2_q', 'chr2_q'): 522
INFO:coolpuppy:('chr17_p', 'chr17_p'): 262
INFO:coolpuppy:('chr17_q', 'chr17_q'): 1235
INFO:coolpuppy:Total number of piled up windows: 2306
plotpup.plot(pup,
cols="orientation",
col_order=["-+", "--", "++", "+-"],
score=False, cmap='coolwarm', scale='log',
sym=True, vmax=2,
height=2)
<seaborn.axisgrid.FacetGrid at 0x2aab347cf310>
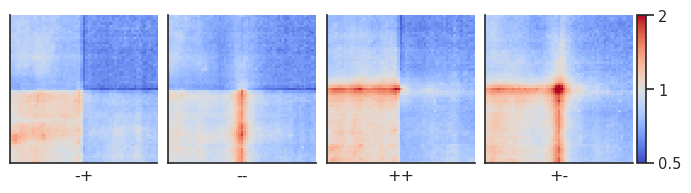
Let’s compare the ++ to the – CTCF motif orientation pileups. First, we have to create two separate pileup dataframes from the strand-separated pileups. Alternatively, you could generate two new pileups and store them. Importantly, the two pileups cannot differ with regards to the columns they contain and the resolution, flank size etc. they’ve been generated using.
pup_plus = pup.loc[pup["orientation"]=="++"].drop(columns=["strand1", "strand2", "orientation"])
pup_minus = pup.loc[pup["orientation"]=="--"].drop(columns=["strand1", "strand2", "orientation"])
pup_divide = divide_pups(pup_plus, pup_minus)
plotpup.plot(pup_divide,
score=False, cmap='PuOr_r', scale='log',
sym=True, height=4)
<seaborn.axisgrid.FacetGrid at 0x2aab344cc970>
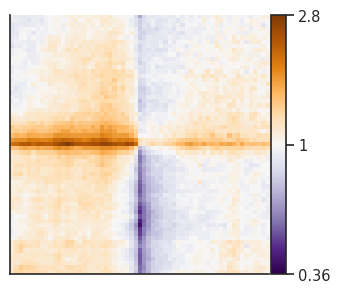
Stripe stackups¶
Oftentimes, as seen in the examples above, the interactions between regions are not just focal, but seen as stripes with enrichment along the vertical/horizontal axis from one or both of the anchor points. In the CTCF pileups from above we see a very strong corner stripe between +- sites, so let’s try to plot these individual stripes. Below is a schematic of what is meant by the different types of stripes.
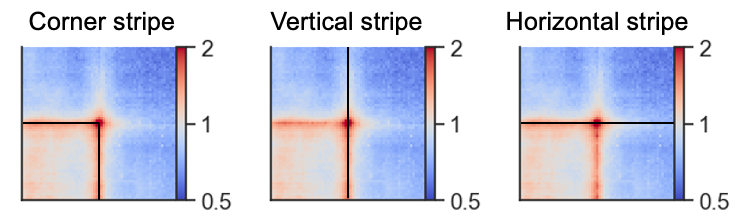
We first have store this information when generating the pileup using the store_stripes=True argument which will add the columns vertical_stripe, and horizontal_stripe to the output. These are used to calculate the corner stripe in the plotting function.
pup = coolpup.pileup(clr, sites, features_format='bed', view_df=hg38_arms,
expected_df=expected,
by_strand=True, mindist=100_000, maxdist=1_000_000,
flank=300_000, nproc=2,
store_stripes=True)
INFO:coolpuppy:('chr2_p', 'chr2_p'): 287
INFO:coolpuppy:('chr2_q', 'chr2_q'): 522
INFO:coolpuppy:('chr17_p', 'chr17_p'): 262
INFO:coolpuppy:('chr17_q', 'chr17_q'): 1235
INFO:coolpuppy:Total number of piled up windows: 2306
We can plot the stripes using the the plot_stripes function
sns.set(font_scale = 1.3, style="ticks")
plotpup.plot_stripes(pup.loc[(pup["strand1"] == "+") &
(pup["strand2"] == "-"),:],
vmax=10, height=4,
stripe="vertical_stripe", stripe_sort="sum",
plot_ticks=True)
<seaborn.axisgrid.FacetGrid at 0x2aab347b26a0>
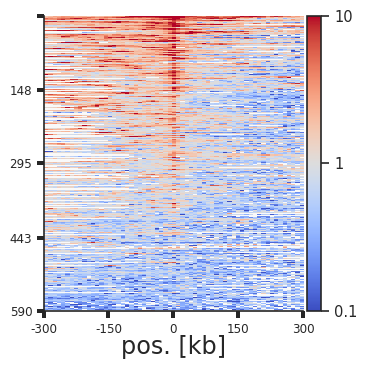
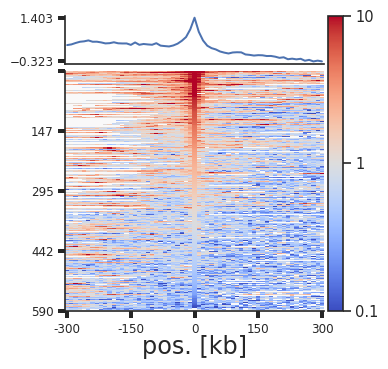
Each line of the above plot represents the “corner stripe” between two regions. These pairs are sorted by the sum of the stripe by default, but we can also sort them by the central pixel, i.e. the pixel where the two regions of interest interact, with the stripe_sort argument. We can further save the pairs in the sorted order using out_sorted_bedpe. This file can then be used to inspect individual pairs with high contact frequencies. We can also add a lineplot with the average signal above the stripes using lineplot (note that this only works for single stripe plots.)
plotpup.plot_stripes(pup.loc[(pup["strand1"] == "+") &
(pup["strand2"] == "-"),:],
vmax=10, height=4,
stripe="corner_stripe", plot_ticks=True,
stripe_sort="center_pixel",
out_sorted_bedpe="CTCF_+-_sorted_centerpixel.bedpe",
lineplot=True)
<seaborn.axisgrid.FacetGrid at 0x2aab35599ac0>
Rescaling¶
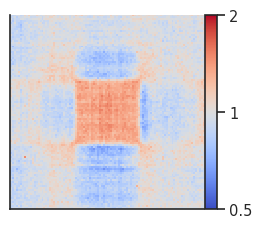
Pileups can also be rescaled to visualise enrichment within regions of interests of different sizes using rescale=True. The rescale_flank value represents how large the flanks are compared to the region of interest, where 1 is equal in size and for example 3 will be three times the size. The number of pixels in the final plot after rescaling is set with rescale_size. Let’s try this for A compartment interactions.
# Generate new expected file for whole chromosomes
expected_hg38_cis = expected_cis(
clr,
chunksize=1000000
)
expected_hg38_cis.to_csv('test_expected_hg38_cis.tsv', sep='\t', index=False, header=True) # To use in CLI
#Load the cooler at 100kb resolution
clr_100kb = cooler.Cooler(f'{cool_file}::/resolutions/100000')
# We need to download the hg38 genome to calculate GC content in the 100 kb bins
# to phase the compartment calling
# (see https://cooltools.readthedocs.io/en/latest/notebooks/compartments_and_saddles.html for details)
if not os.path.isfile('./hg38.fa'):
subprocess.call('wget https://hgdownload.cse.ucsc.edu/goldenpath/hg38/bigZips/hg38.fa.gz', shell=True)
subprocess.call('gunzip hg38.fa.gz', shell=True)
hg38_genome = bioframe.load_fasta('./hg38.fa');
bins = clr_100kb.bins()[:]
gc_cov = bioframe.frac_gc(bins[['chrom', 'start', 'end']], hg38_genome)
gc_cov.to_csv('hg38_gc_cov_100kb.tsv',index=False,sep='\t') # To use it in CLI
# Calculate eigenvectors at 100 kb resolution using cooltools, phased by GC coverage
cis_eigs = cooltools.eigs_cis(clr_100kb,
gc_cov,
n_eigs=3)
eigenvector_track = cis_eigs[1][['chrom','start','end','E1']]
# Extract and merge A compartments (eigenvector E1>0)
A_compartments = bioframe.merge(eigenvector_track[eigenvector_track["E1"] > 0],
min_dist=0)
# Select compartments at least 500kb in size
A_compartments = A_compartments[A_compartments["n_intervals"] >= 5]
A_compartments[["chrom", "start", "end"]].to_csv("A_compartments.bed", sep="\t", header=None, index=False) # To use it in CLI
pup = coolpup.pileup(clr, A_compartments, features_format='bed',
expected_df=expected_hg38_cis,
rescale=True, rescale_flank=1, rescale_size=99,
nproc=2)
INFO:coolpuppy:Rescaling with rescale_flank = 1 to 99x99 pixels
INFO:coolpuppy:('chr17', 'chr17'): 253
INFO:coolpuppy:Total number of piled up windows: 1528
fg = plotpup.plot(pup,
score=False, cmap='coolwarm', scale='log',
sym=True, vmax=2, height=3)
Trans (inter-chromosomal) pileups¶
We can also perform pileups between regions on different chromosomes. We will try this for A-A compartments again. To perform the same analysis between chromosomes, we first need to generate a new expected file (or use shifted controls) and then run the analysis with trans=True.
# Calculate expected interactions between chromosomes
trans_expected = expected_trans(
clr,
chunksize=1000000)
trans_expected.to_csv('test_expected_trans.tsv', sep='\t', index=False, header=True) # Let's save to use in CLI
pup = coolpup.pileup(clr, A_compartments, features_format='bed',
expected_df=trans_expected, trans=True,
rescale=True, rescale_flank=1, rescale_size=99)
/gpfs/igmmfs01/eddie/wendy-lab/elias/coolpuppy_trans/coolpuppy/coolpuppy/coolpup.py:2150: UserWarning: Ignoring maxdist when using trans
CC = CoordCreator(
INFO:coolpuppy:Rescaling with rescale_flank = 1 to 99x99 pixels
INFO:coolpuppy:('chr2', 'chr17'): 1173
INFO:coolpuppy:Total number of piled up windows: 1173
fg = plotpup.plot(pup,
score=False, cmap='coolwarm', scale='log',
sym=True, vmax=2, height=3)
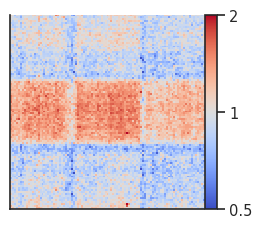
Here we can see rescaled A-A interactions across chromosomes. The pileups look less good than in cis due to the sparse data used in this example.